Bridging Genome to Function: Post-Genome Science
Connecting Differences to Pathways
Motivation
- If 300 genes are differentially expressed, what kind of biological pathways are affected?
- What are the implications of DNA-microarray/ChIP-seq results in the clinical perspective?
![]()
- I cannot lose weight because my genes involved in fat synthesis are upregulated compared to others.
Example of KEGG Pathways
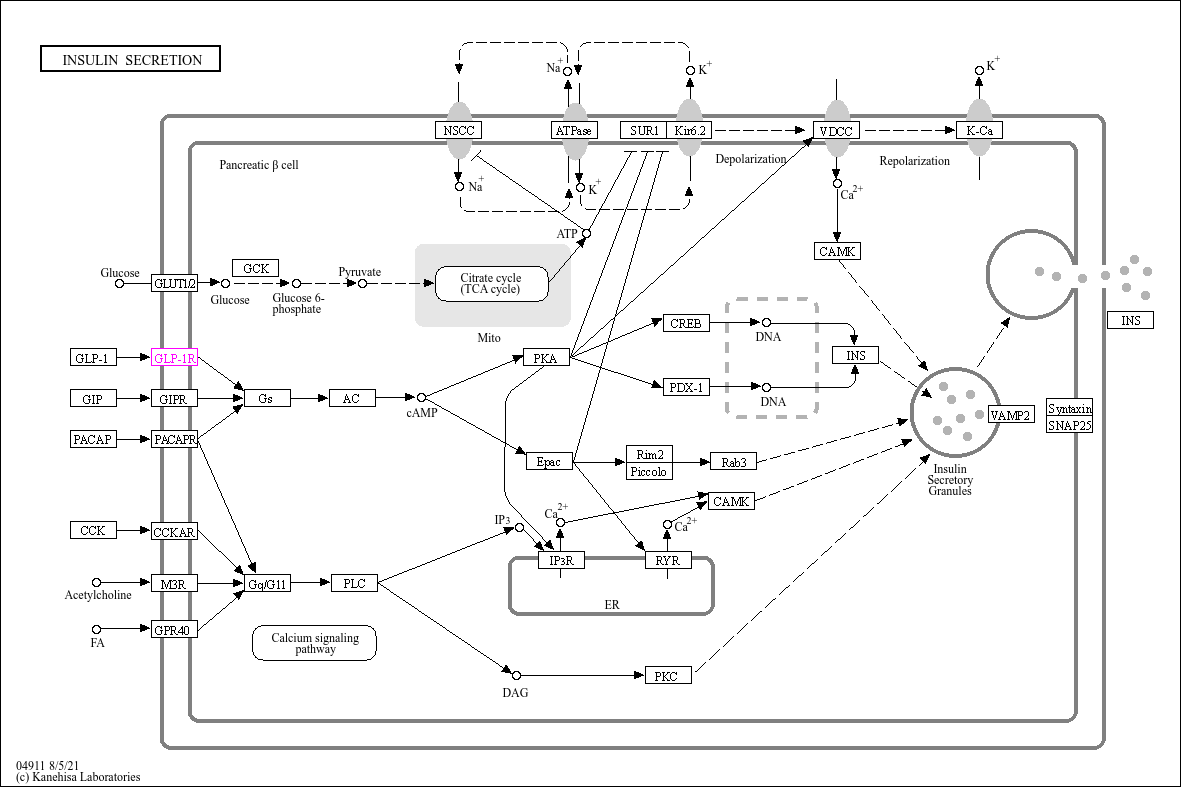
Example of insulin annotation and insulin secretion process in KEGG
Example of GO Pathways
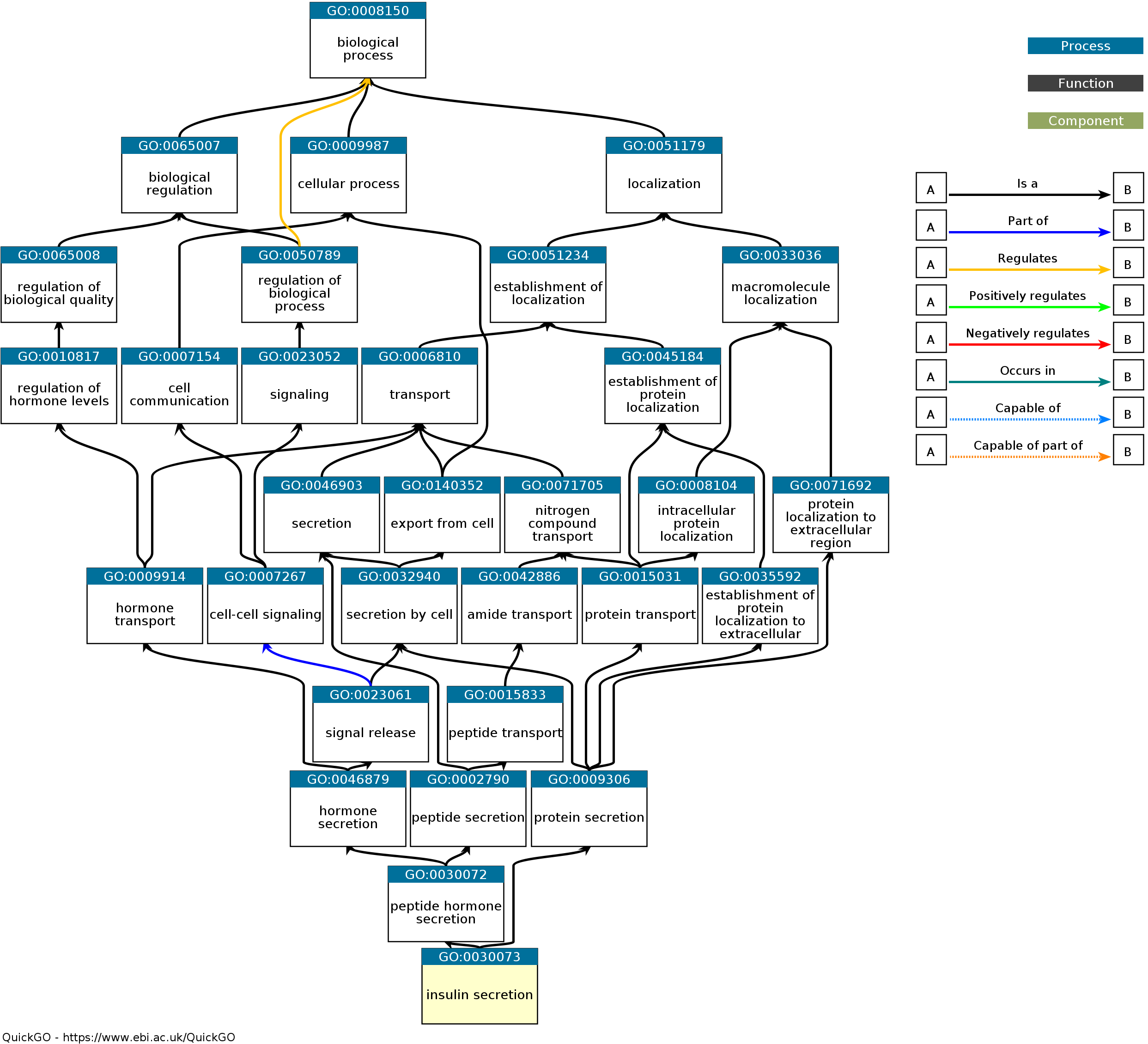
Example of insulin annotation and insulin secretion process in GO
Connecting Genes to Biological Functions
Enrichment Analysis Summarizes identified differences in genes associated with common functions.
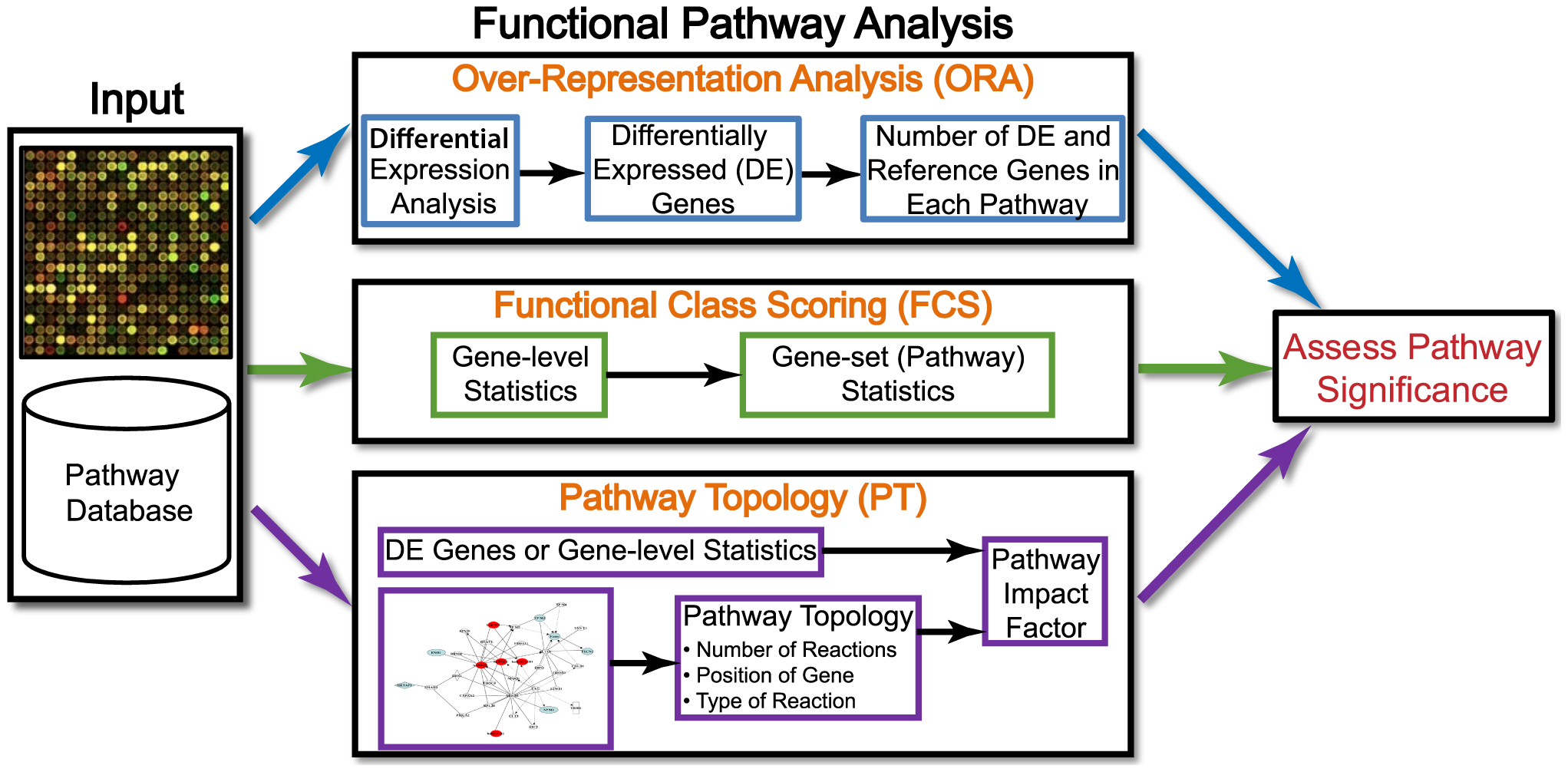
Genomic Regions Enrichment of Annotations Tool
- Motivation: Do cis-regulatory elements associate with specific pathways?
Problem Formulation
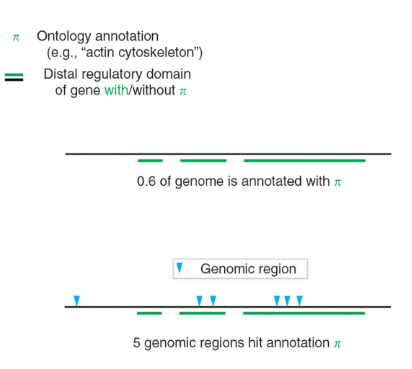
- Given a 1000 bp sequence
- From the existing database, 600 bp (located in the figure) is annotated with the functional path \(\pi\)
- ChIP-seq identified 6 enriched regions bound by protein, among them, 5 are in the annotated region \(\pi\)
- Question: If the ChIP-Seq identified regions occur randomly, what is the probability that ChIP-Seq identified regions fall into the regulatory domain \(\pi\)?
Over-Representation Analysis
- Motivation: Are biological pathways enriched (over-represented) in an experimentally-derived gene list, e.g., a list of differentially expressed genes (DEGs)?
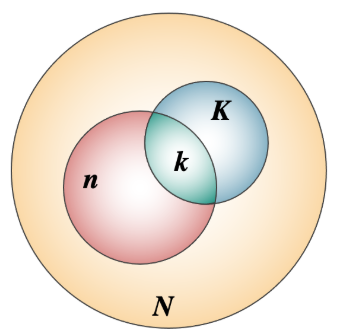
- \(N\): Background set
- \(n\): Differentially expressed genes
- \(K\): Genes in the Pathway \(\pi\)
- \(k\): Overlapping set
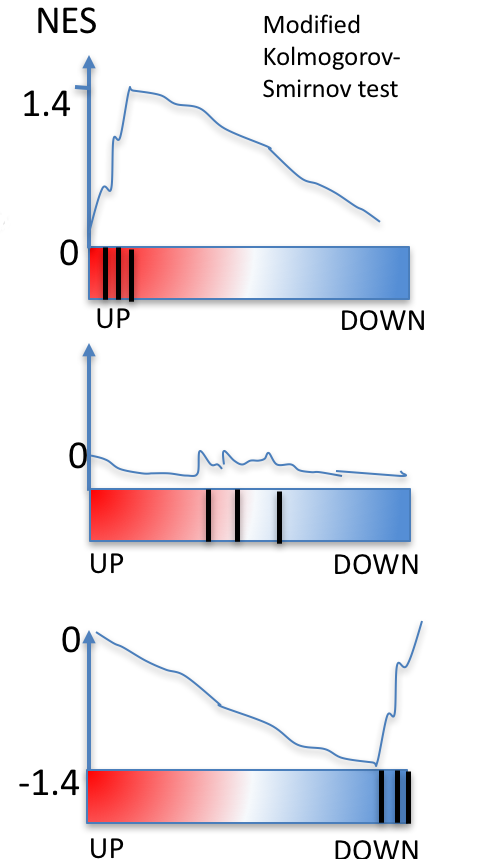
Gene Set Enrichment Analysis (GSEA)
- Sort genes (by log fold change)
- Calculate running sum from the sorted gene list:
- Increase while in the pathway
- Decrease while not in the pathway
- Find the maximum running sum
- Permute the label to calculate p-value
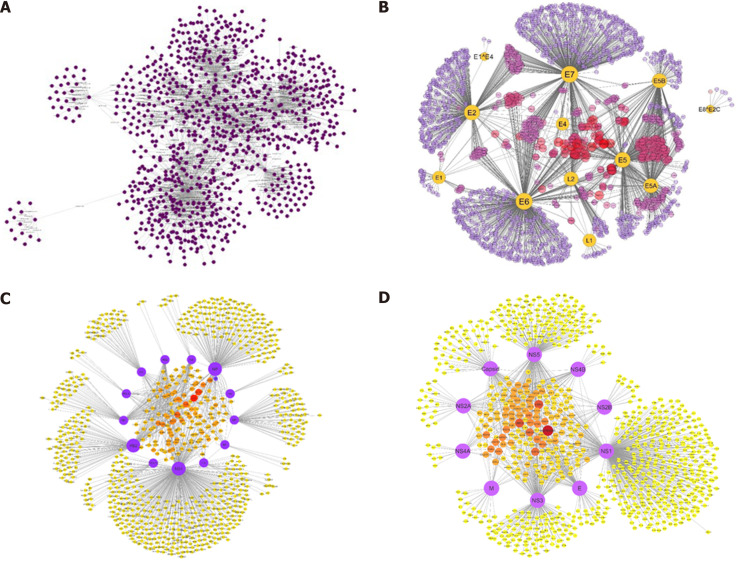
Complexity of Interactions
In reality, proteins can interact together, and it’s more complex than what we’ve seen in KEGG.
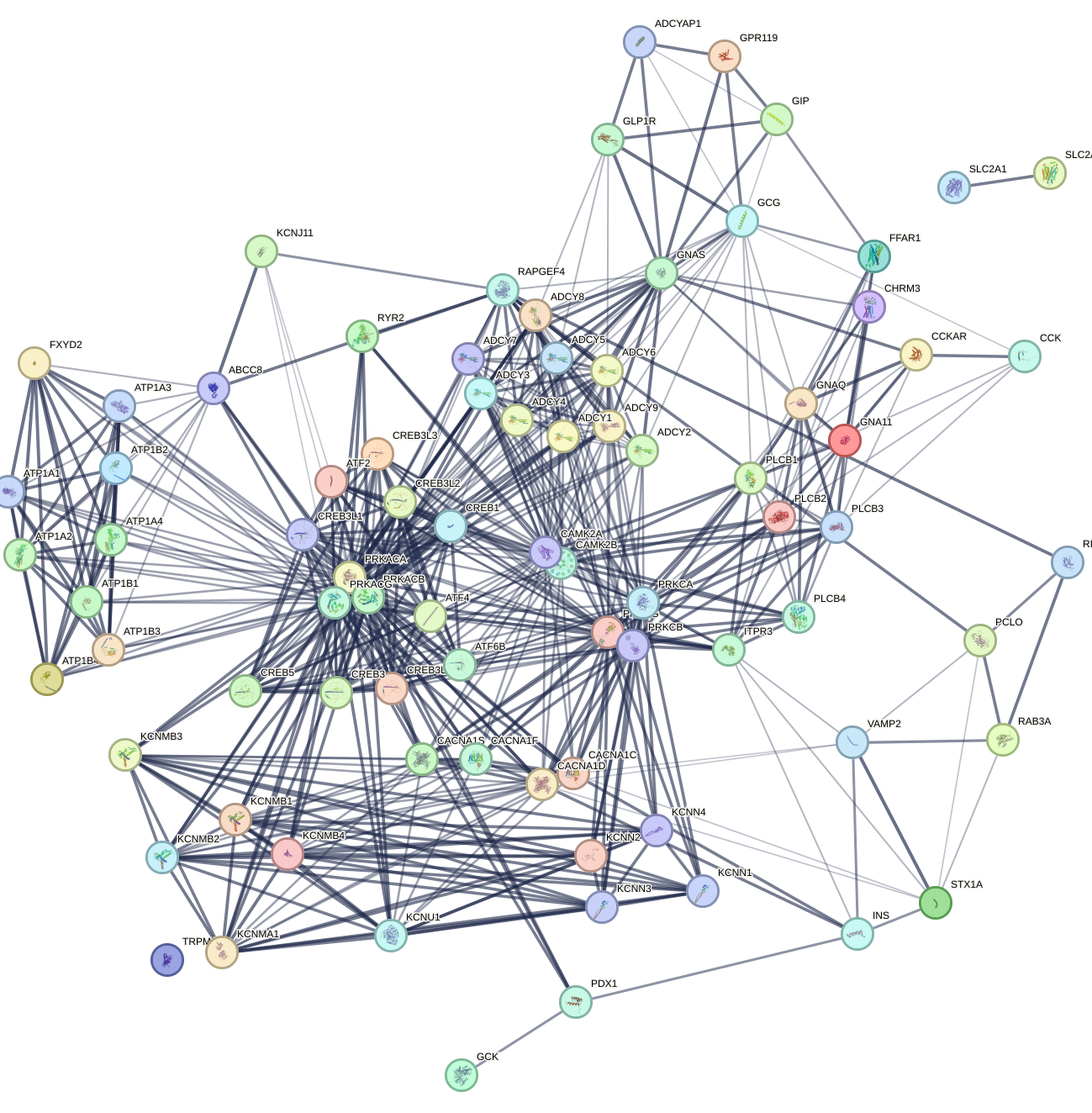
Reasons
Proteins could interact with each other in other pathways (e.g., some interactions can be related to insulin resistance but not insulin secretion, so KEGG does not show it)
Scientific advancements and experiments:
- Gene co-expression
- Co-occurrence
Importance of a Node
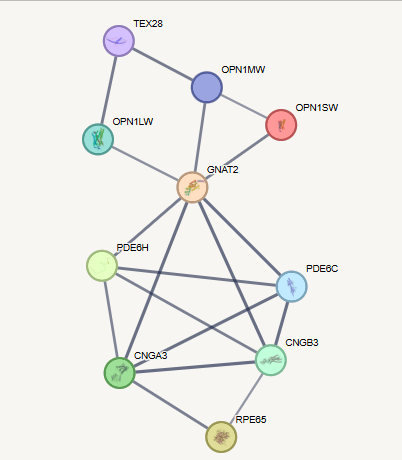
Degree
- An intuitive measurement of the importance of a node
- Number of edges connected to the node
\[\begin{equation*} \text{Degree(i)}=\sum_{j=0}^{\vert N\vert}e_{ij} \end{equation*}\]
Degree of:
- GNAT2: 7
- TEX28: 2
Local Community of a Network
Clustering Coefficient
- How many friends of friends are also my friends (Triangles)
\[\begin{equation*} \begin{split} \text{Clustering coefficient(i)}&=\frac{L_i}{\frac{k_i(k_i-1)}{2}}\\ &=\frac{2L_i}{k_i(k_i-1)} \end{split} \end{equation*}\]
- \(L_i\): Number of triangles including node \(i\)
- \(k_i\): Number of nodes connected to node \(i\)
Clustering coefficient of:
- GNAT2: \(\frac{7*2}{7*6}=0.33\), TEX28: \(0\)
Application of PPI
- Exploring disease mechanisms
- Drug discovery