stateDiagram
i : Input text
state i{
T0 : Text A1
T1 : Text A2
}
r : Hidden layers
state r{
RNN1 : Node1
RNN2 : Node2
RNN3 : Node3
RNN4 : Node4
}
o : Output layers
state o{
o1 : Output layer 1
o2 : Output layer 2
}
T0 --> RNN1
T1 --> RNN1
T0 --> RNN2
T1 --> RNN2
T0 --> RNN3
T1 --> RNN3
T0 --> RNN4
T1 --> RNN4
RNN1 --> o1
RNN2 --> o1
RNN3 --> o1
RNN1 --> o2
RNN2 --> o2
RNN3 --> o2
Media Reporting and Suicide
Natural language processing evaluation and monitoring
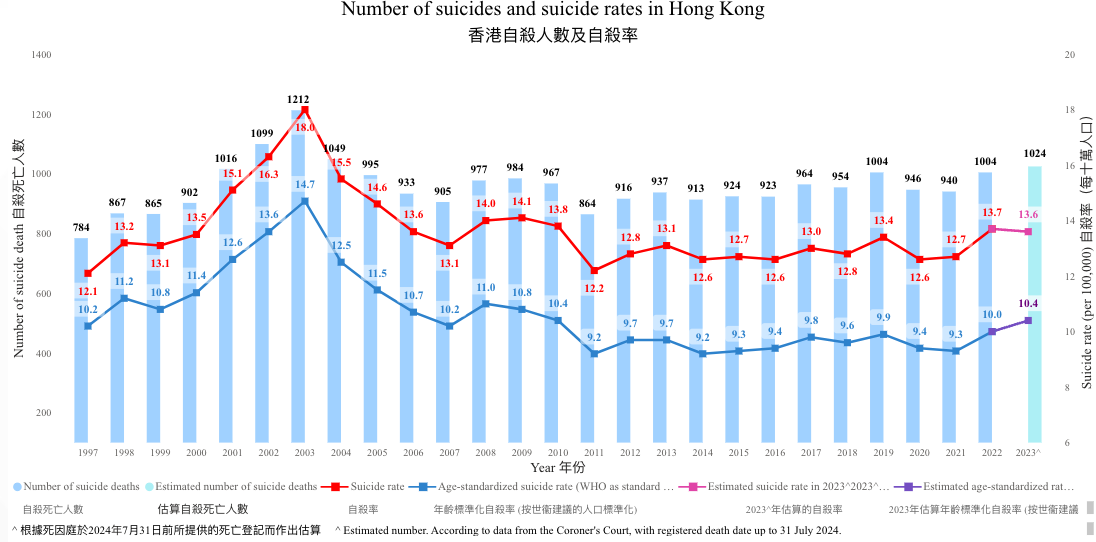
Suicide rate in Hong Kong
- Hong Kong’s age-standardized suicide rate: 9.5 per 100,000 people
- The historical peak was in 2003 during the SARS outbreak and financial crisis
- Heterogeneity within subgroups
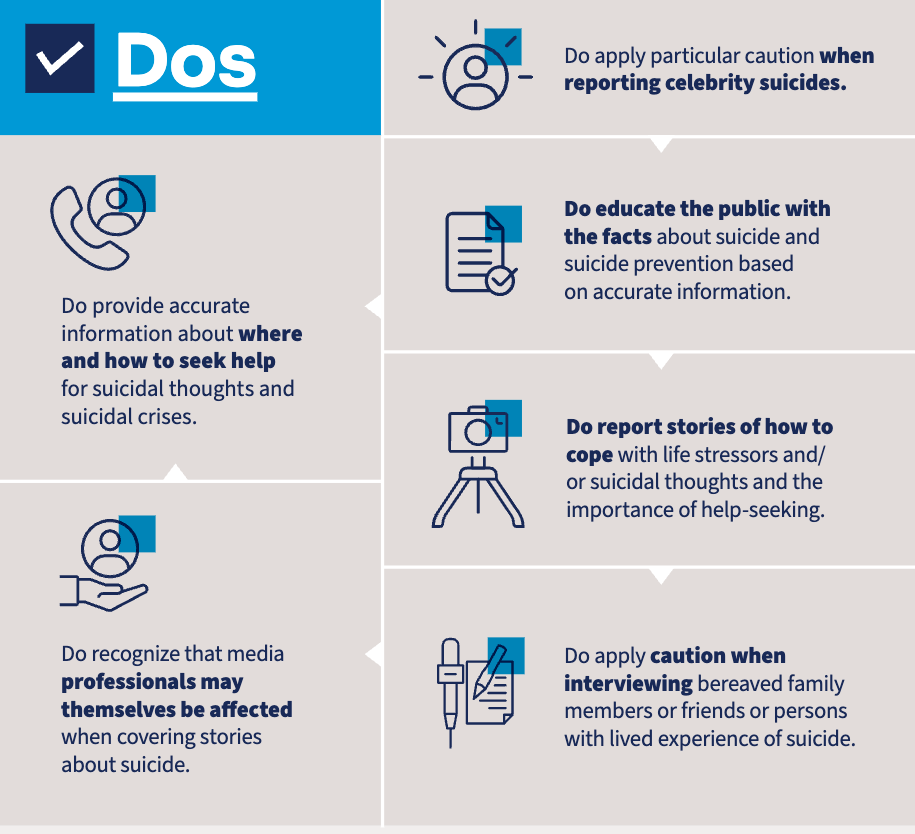
Dos
- Provide
- helpful information
- facts on suicide and prevention efforts
- Acknowledge that reporters may be affected
- Report how to cope and seek help
- Exercise caution with
- Celebrity suicides
- Interviewing bereaved family and friends
Don’ts
- Content
- Methods
- Details
- Style
- Over-simplifying reasons
- Language use
- Sensational language
- Romanticizing
- Additional content
- Visual and audio content
- Social media links

Attention, transformer and LLM
- Attention mechanism introduced in Vaswani et al. (2017) Attention is All You Need, which uses self-attention mechanisms to process input data efficiently.
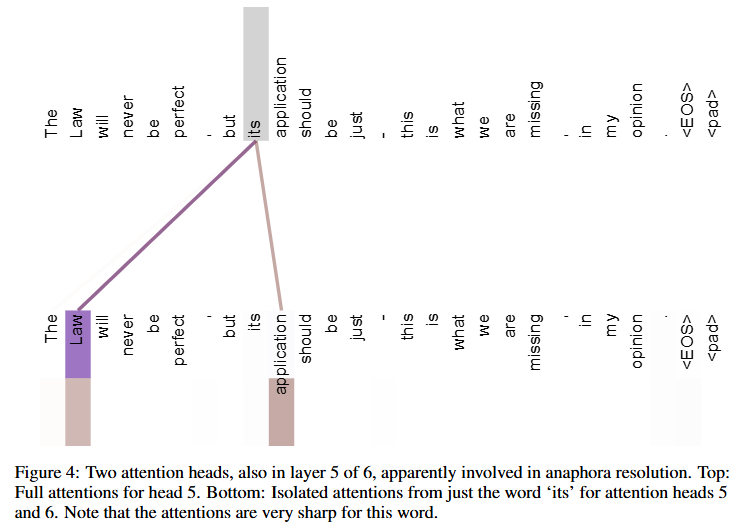
- Instead of memorizing previous state, attention mechanism dynamically calculates the importance of each input based on the context.
stateDiagram
i : Input text
state i{
T0 : Text A1
T1 : Text A2
T2 : Text A3
}
e : Embedding
state e {
Query1 : Query A1
Key1 : Key A1
Key2 : Key A2
Key3 : Key A3
Value1 : Value A1
Value2 : Value A2
Value3 : Value A3
}
w : Attention Weight
state w {
weight1 : Weight A1
weight2 : Weight A2
weight3 : Weight A3
}
T0 --> Query1
T0 --> Key1
T0 --> Value1
T1 --> Key2
T1 --> Value2
T2 --> Key3
T2 --> Value3
Query1 --> weight1
Key1 --> weight1
Query1 --> weight2
Key2 --> weight2
Query1 --> weight3
Key3 --> weight3
weight1 --> output
Value1 --> output
weight2 --> output
Value2 --> output
weight3 --> output
Value3 --> output
Subword Tokenization
Encoding based on the word are potentially prone to
- Mis-spelling
- Hard to cater to grammatical variations
Subword Tokenization Breaking word into some smaller subwords, in addition to address above issue
- Higher chance to guess out of dictionary terms

Embedding
Count-based embedding
- Sentence level: we create a vocabulary (actually token) corpus and create an adjacency matrix \(|V|\times |V|\) where
- Each element \(v_{ij}\) means how many times word \(i\) and \(j\) is next to each other (1-gram)
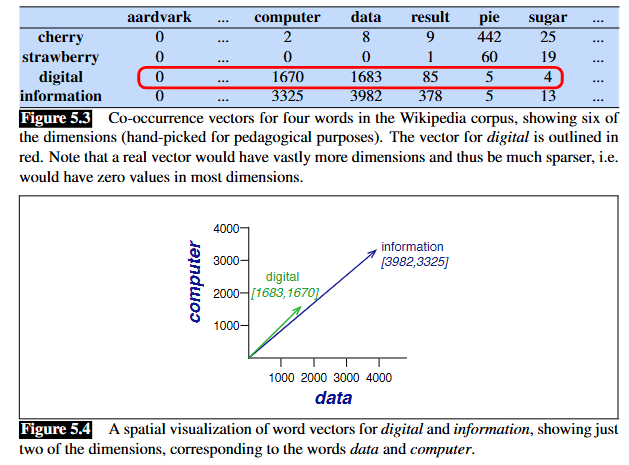
Word2vec
Another brutal way is let the machine embedding themselves through self-supervise learning and auto-encoder.
- Input: Sentence + word
- Output: Word next to them within 2 words
Discussion
It is obvious that these tokens were represented in high dimension and sparse format. What are the potential implication if we directly used these embedding for analysis?
Techniques of customizing LLM
Count-based embedding
- Prompting
- Instructing LLM the task
- Retrieval-Augmented Generation (RAG)
- Giving external reference
- Fine-tuning
- Retraining model
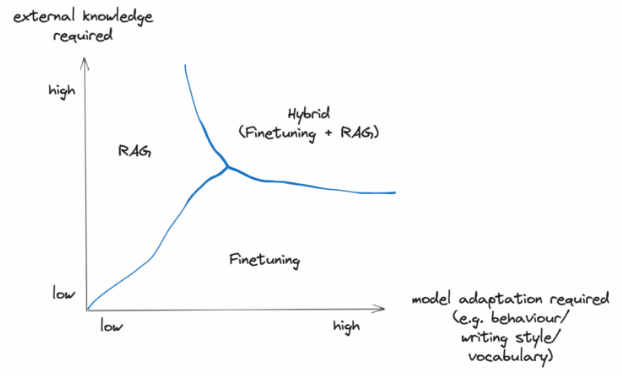
Consideration of different customization
Budget
![GPT-5 quotation price at 2025-09-01]()
Scalability Does the model need to be very generalizable
- Small, precise model v.s. large generalizable model

Temperature sampling
- Adjusting the chance of being selected in the random sampling.
Recalling \(w \sim \text{Mult}(1,p)\)
Therefore, we can using a bayesian to influence this distribution.
- Some thoughts
- Uniform dirichlet prior => It will be normalized at the end
- Informative prior => how to generate informative prior?
Solution: Exponentially scaling the logit with factor \(\frac{1}{\tau}\)

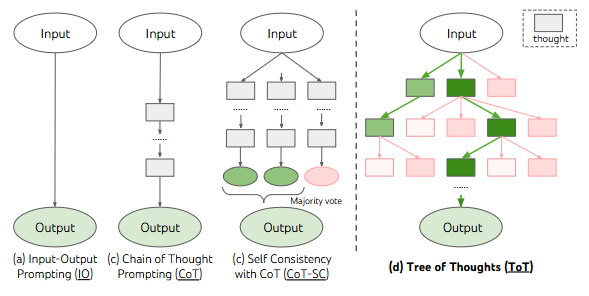
Self-consistency CoT and Tree of Thought (ToT)
Self-consistency CoT Wang et al. (2022) Random forest of LLM
- Generate more possible outcomes
- Majority voting of the results
Tree of Thought Yao et al. (2023) Decision tree
- LLM decomposes the task into several strategies and develops strategies
- Evaluating the output whether it has answered the original question
Ethical and Safety Issues
Bias
Data source is the major contributor of the model bias. The model gets the inference based on your input text, which could convey social and cultural bias.
Hallucination
It is prominent in LLM that it generates text based on a probabilistic way instead of facts and references. It can create new things that do not exist at all.
Safety use
Sensitive content, violence, sex, death, could occur if you intentionally instruct them to do so. Safely using these tools is critical
